Alexey Grigoriev, Machine Learning Engineer, ID R&D

Social networks and messaging apps have changed the way people communicate with each other. For many, they are a part of daily life. It also means that our faces and voices are now readily available not only to our friends and family, but also to the fraudsters. At the same time, the quality of sensors, mobile phones, and screens is rapidly advancing. Even low-end mobile phones can have high-quality cameras and displays. The combination of these factors raises the question of the vulnerability of modern biometric systems and makes facial anti-spoofing an important area of research.
The importance of data in creating passive Facial Liveness detection
Advancing research in facial anti-spoofing is not possible without data. Big data is paramount to building a powerful facial liveness detector because convolutional neural networks have millions of parameters, and the optimization process is a bit tricky. The well-trained network is composed of properly configured parameters. When we feed the input image into this function, it returns the class of input indicating whether it is spoof or not. To train a detector, we collect a set of photos or videos of many live people and a set of spoofs. This data is divided into a training and test set. The training data is used to train the detector, and the test set contains unseen or out-of-domain images used to evaluate the detector. At this step, the quality and diversity of the data are essential. Not paying attention to the data will result in an inadequate detector—garbage in, garbage out.
While training facial anti-spoofing, we may face underfitting and overfitting problems related to the complexity of the data and the network. Overfitting may happen when the amount and complexity of training data is small but the model is complex. For example, we ask ten people to create a simple 2d mask attack and make a few selfies under the same conditions. If we train the network with too many parameters, it will remember the training dataset and perform poorly on unseen samples. On the other hand, underfitting may happen when the dataset contains a large amount of complex data. If we train a simple network with limited features on such a dataset, it will not be able to extract common patterns in live and spoof images. It will perform poorly on unseen samples as well.
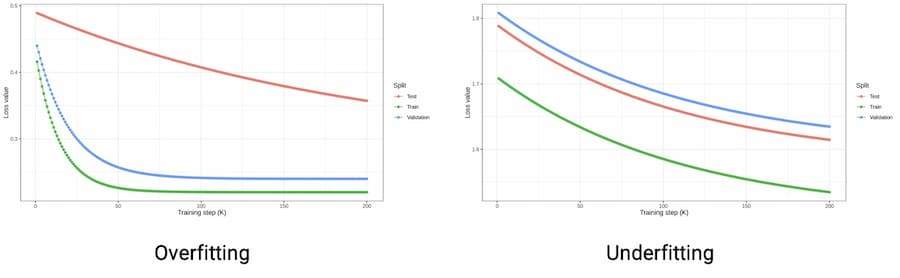
These problems substantially impact the ability of the network to extract common patterns from data and correctly classify test samples. For example, screen-replay and mobile attacks use a variety of cameras and devices. The various combinations may produce different moire patterns in photos. If we train a network on a large number of diverse screens and mobile replays, it will be able to extract common moire patterns and ‘see’ them in unseen data. Each attack has cues that can help to identify the sample as an attack — for example, moire in replay attacks, borders on 2d-masks, or unusual illumination in printed photos. This is discussed more in my blog post on Computer Vision.
The well-trained network can spot such cues even in unseen data. This is also known as “generalization.” A network with strong generalization abilities can properly classify the unseen and out-of-domain attacks as spoofs. However, to achieve such performance, we need to collect a high-quality and diverse dataset.
Publicly available data for AI training
Thanks to the computer vision community, significant effort has been put into building representative datasets of live images and various types of spoofs. These include:
- The OULU dataset — Collected in 2017, 57 subjects participated in the data collection. Authors collected 1980 images and 3960 videos of live subjects and various spoofs attacks, such as printed photos and video replays. Moreover, multiple devices were used (Samsung Galaxy S6. Oppo N3, etc.)
- The SiW dataset — Collected in 2018 with race bias in mind, 165 subjects from different ethnicities took part in the data collection. The dataset contains various types of screen replays and printed attacks. It also includes 1320 images and 3300 videos.
- CelebA spoof – This is a recent attempt to build a diverse and large-scale dataset. It has 625537 images of 10177 unique objects. Each image has 43 attributes, in which 3 attributes are related to the spoof image, including information about spoof type, capturing environment, and illumination conditions. Forty attributes are associated with the live image, containing information about the human face (lip, hair, etc.) and extra information about eyeglasses, hats, etc.
Comparison of the internal ID R&D anti-spoofing dataset and existing public datasets
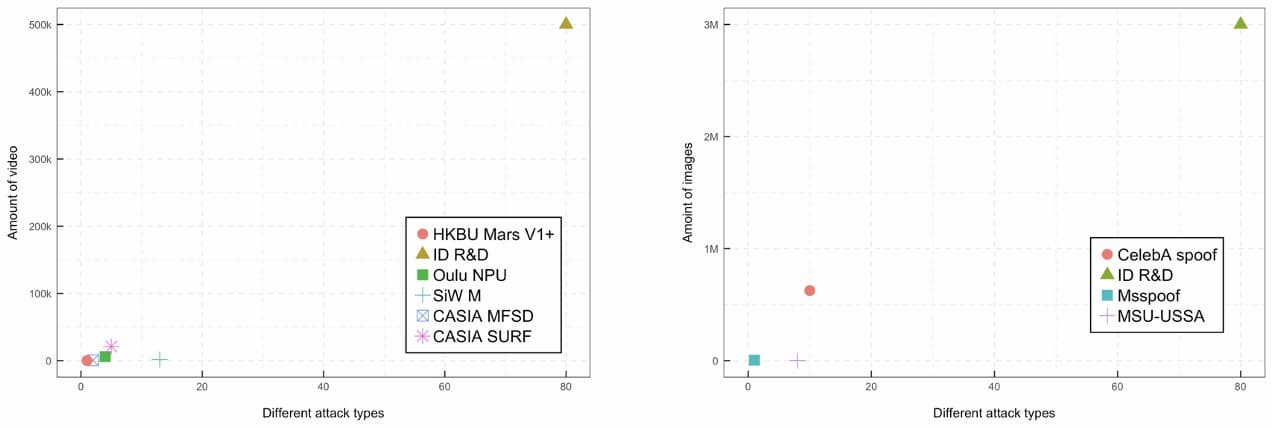
The datasets summarized above have made an invaluable impact on liveness detection development. However, they still have some limitations. First, due to the required human effort, there are no planned updates for these datasets and no one is available to support or fix issues with labeling. Second, they still do not provide enough data to build a robust spoof detector. The modern convolutional neural networks require millions of images. Third, the diversity of the dataset is not large enough to create a spoof detector that will work with different demographics around the world. A large amount of data is needed for each domain where spoof detection is required. To build a best-in-class spoof detector, we always need to be a step ahead of criminals in terms of data and creativity.
About ID R&D’s AI training for passive facial liveness
At ID R&D we have a dedicated data team to address the challenge of collecting the data needed to develop and train a high-performance facial liveness detector. The internal facial anti-spoofing dataset has grown significantly through the years. The data team is constantly updating our internal spoof/live dataset to ensure diversity and quality. They devise creative attacks that result in our facial liveness detector being more robust to a wide range of spoofs. They also actively work on reducing bias in data, including gaps in race, gender, and age. The collected training and test data include millions and thousands of images, respectively. By collecting data from around the world and creating flexible algorithms, our solution achieves best-in-class accuracy across a variety of conditions.
Learn more about ID R&D passive facial liveness.