In the modern era, it’s no secret that AI-driven products heavily rely on data; speech processing tasks are no exception. Access to extensive, well-labeled, and representative datasets is crucial for training highly accurate models. Recent showcases of excellence, such as the VoxSRC challenges, stand as poignant reminders of the pivotal role played by robust datasets in shaping cutting-edge advancements. Notably, ID R&D has emerged as a frontrunner, clinching the top honors in two consecutive years, a testament to our unwavering commitment to pushing the boundaries of security, contact centers, and personal assistants.
In the modern era, it’s no secret that AI-driven products heavily rely on data; speech processing tasks are no exception. Access to extensive, well-labeled, and representative datasets is crucial for training highly accurate models. Recent showcases of excellence, such as the VoxSRC challenges, stand as poignant reminders of the pivotal role played by robust datasets in shaping cutting-edge advancements. Notably, ID R&D has emerged as a frontrunner, clinching the top honors in two consecutive years, a testament to our unwavering commitment to pushing the boundaries of security, contact centers, and personal assistants.
At the core of our endeavors lies the VoxTube dataset, meticulously curated to embody the essence of excellence in speaker recognition. With a keen focus on key facets, we have sculpted a repository that not only meets but exceeds the stringent demands of modern AI training:
Embracing Diversity in Data. This aims to include a wide range of speakers in the dataset to ensure diversity. The rationale is to train models that can distinguish between different speakers effectively. A greater number of speakers in the dataset enhances the model’s ability to recognize and differentiate between various voice patterns, tones, and nuances, which is crucial for achieving high accuracy in speaker recognition tasks.
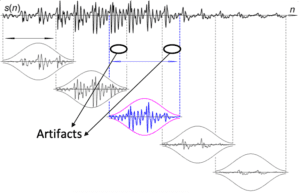
Capturing Acoustic Variability. This includes capturing speakers in different acoustic environments (e.g., noisy, quiet, indoor, outdoor), different emotional states (e.g., happiness, sadness, anger) and collecting voice data over a significant period allows the dataset to reflect changes in a speaker’s voice over time. The main differentiator of this dataset compared to its predecessor is the significant period of time (years) between audio recordings of the same speaker.
Ensuring Linguistic Inclusivity. The dataset also aims to include voices from 10 different languages.
Unique Data Collection Strategies for Speaker Recognition Data
During the data collection process for the VoxTube dataset, ID R&D researchers implemented a strategy focused on leveraging a video hosting platform, Youtube. The key aspects of our data collection methodology included:
Primary Speaker Identification: Our process began with the assumption that each Youtube channel features a primary speaker, allowing us to target the specific voice for collection from the channel.
Two-Level Unsupervised Clustering: We employed an innovative two-level unsupervised clustering of audio embeddings. This technique was crucial for grouping similar voice samples together without the need for predefined labels, enhancing the dataset’s accuracy and relevance.
Independent Channel Processing: A significant advantage of our approach was the independent processing of each Youtube channel. This method ensured efficient data collection by enabling parallel processing of multiple channels, significantly scaling up the data acquisition capabilities.
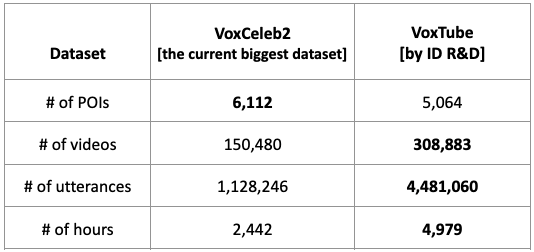
In summary, VoxTube is a dataset that features more than 5,000 speakers, each with 60 distinct recording sessions, covering more than 10 languages. The dataset offers approximately 5,000 hours of speech and is considered one of the largest datasets for speaker recognition in this regard. The data is delivered in the form of JSON files containing the links to corresponding video files and corresponding segments with timestamps.
As staunch advocates of scientific progress, ID R&D takes immense pride in our contribution to the global research community. We firmly believe that VoxTube will emerge as a cornerstone resource for speaker recognition researchers, unlocking new frontiers in AI-driven innovation. For a deeper dive into the intricacies of our dataset, we invite you to explore our scientific paper presented at the esteemed Interspeech 2023 conference.