APCER e BPCER são siglas para taxas de erro usadas para quantificar o desempenho de sistemas de detecção de ataque de apresentação (PAD). Este artigo fornece algumas informações básicas sobre como eles são usados e de onde vieram.
A detecção de ataque de apresentação (PAD) protege um processo de verificação de identidade digital contra fraudes. Quando um usuário apresenta dados biométricos ou documentos remotamente como prova de sua identidade, suas imagens biométricas devem ser demonstradas como “vivas” e seus documentos de identidade devem ser comprovados como estando em sua posse física. Caso contrário, é possível que um fraudador apresente “falsificações” não vivas para deturpar intencionalmente a sua identidade. Exemplos de falsificações são fotos faciais impressas e copiadas, máscaras faciais e imagens de documentos de identidade exibidos em uma tela digital.
Idealmente, a detecção de ataques de apresentação deve minimizar o atrito para usuários legítimos e também evitar fornecer informações aos fraudadores sobre como burlar o sistema. Mais informações sobre ataques de apresentação e detecção de atividade podem ser encontradas aqui , bem como como funciona uma abordagem de imagem única e sem atrito para o liveness facial , além de um exemplo de como ela pode reduzir drasticamente o abandono do cliente .
No caso de algoritmos de matching biométrico, como os usados para reconhecimento facial, é útil medir e relatar como eles se comportam em uma amostra de dados representativa, a fim de prever o desempenho do algoritmo em ambiente de produção. Para um caso de uso de autenticação, isso pode significar uma previsão do nível de segurança fornecido e do impacto na experiência do usuário. O mesmo pode ser dito dos algoritmos de detecção de ataques de apresentação. Quão frequentes são os erros quando é feita uma avaliação de uma imagem ao vivo ou de uma falsificação?
APCER e BPCER são siglas para taxas de erro usadas para medir o desempenho dos subsistemas PAD. Elas significam “taxa de erro de classificação de ataque de apresentação” e “taxa de erro de classificação de apresentação bona fide”, respectivamente. APCER e BPCER servem para quantificar a precisão da classificação de uma imagem como imagem ao vivo ou falsificação e ajudam a determinar a compensação entre segurança e conveniência. Eles são análogos às medições de erro para algoritmos de matching biométrico usados para identificação e verificação: taxas de falso matching (FMR), taxas de falso não matching (FNMR), taxas de falsa aceitação (FAR) e taxas de falsa rejeição (FRR). Elas são similares, mas há razões pelas quais temos três conjuntos de taxas de erro.
Teste estatístico de hipóteses
Um pouco de conhecimento sobre estatísticas e testes de hipóteses ajuda a esclarecer parte da confusão que às vezes é causada pelas diferentes métricas usadas para medir a biometria e o desempenho do PAD. As medições são derivadas de testes estatísticos de hipóteses, um conceito fundamental na investigação científica onde uma hipótese é definida e depois testada para determinar se é de fato verdadeira, com dados empíricos mostrando que o resultado é estatisticamente significativo; isto é, os dados fornecem evidências de uma relação preditiva além da chance probabilística. O conceito tem sido aplicado a testes de desempenho de algoritmos biométricos desde o seu início.
A figura abaixo ilustra a coleta e uso de dados de teste para demonstrar que a “hipótese nula” é verdadeira e não há relação preditiva estatisticamente significativa demonstrada, ou melhor, que a “hipótese alternativa” é verdadeira, indicando que há de fato uma relação preditiva entre variáveis que está além do acaso estatístico. Os dados são recolhidos, um limite é definido e, com base nos resultados, pode-se tirar uma conclusão apoiada por evidências estatísticas. Ou seja, os resultados do teste demonstram uma relação causal ou são resultado do acaso estatístico? Haverá invariavelmente valores discrepantes na coleta e medição de dados, e estes são quantificados para avaliar a fiabilidade dos resultados em termos de probabilidade.
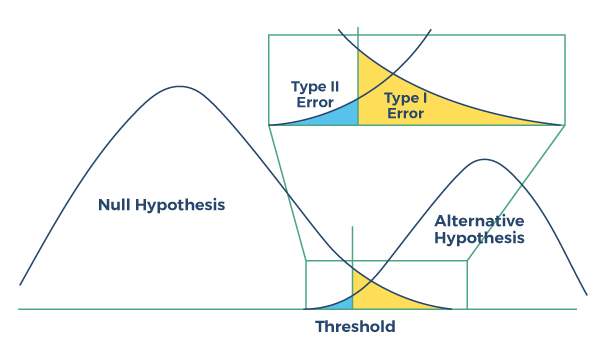 Figura: Teste de hipóteses como modelo para desempenho do classificador
Figura: Teste de hipóteses como modelo para desempenho do classificador
Uma taxa de erro Tipo I mede a frequência de “erros de comissão ”; falso-positivo, onde uma relação ou resultado é determinado e atribuído incorretamente, quando na verdade é devido apenas ao acaso estatístico. A A taxa de erro tipo II mede a frequência dos “erros de omissão ”; falsos negativos , onde um relacionamento ou resultado é erroneamente concluído como inexistente ou devido apenas ao acaso.
Taxas de erro em biometria
Na biometria, o desempenho de um algoritmo de comparação pode ser testado e compreendido com a ajuda da construções de teste de hipóteses. Se a hipótese alternativa puder ser demonstrada como verdadeira com significância estatística, isso servirá como evidência de que os resultados da comparação são precisos e não aleatórios. Mas o que é intuitivo como “hipótese nula” nesta aplicação pode variar de acordo com o caso de uso alvo, causando confusão em termos de qual taxa de erro é qual; isto é, qual resultado representa falsos positivos e qual representa falsos negativos?
Em aplicações de pesquisa biométrica “um-para-muitos”, utilizadas pelas autoridades policiais para identificar uma pessoa desconhecida numa grande base de dados, a hipótese nula é bastante intuitiva: a não correspondência. Uma correspondência biométrica está associada à identificação positiva de um suspeito de infração entre milhares ou mesmo milhões de candidatos.
Em contraste com as aplicações de identificação biométrica, a verificação e autenticação biométrica comparam a biometria de um utilizador legítimo com a sua própria biometria de referência armazenada; ou seja, uma correspondência indica não um mau ator, mas um usuário genuíno. Nesse caso, qual caso é a hipótese nula e qual é a hipótese alternativa torna-se menos intuitivo, uma vez que uma correspondência positiva é o resultado mais comum e “correto”. E ainda assim, para este caso de uso de segurança, é fácil ver por que um resultado “positivo” poderia ser considerado a hipótese alternativa.
Resumindo, em ambos os casos de uso de biometria, a hipótese alternativa é a correspondência biométrica positiva. A confusão vem do fato de que em casos de uso de identificação, a correspondência positiva indica uma ameaça (por exemplo, uma pessoa em um banco de dados de criminosos condenados), enquanto na autenticação, a correspondência negativa indica uma ameaça potencial (alguém tentando se passar por um usuário genuíno ).
Taxas de erro em ataques de apresentação: APCER e BPCER
Ao detectar ataques de apresentação, o software classificador pode usar técnicas para detectar liveness, não-liveness ou ambas, e assim saber quais são as hipóteses nula e alternativa torna-se ainda menos claro; a hipótese nula representa a detecção de uma amostra genuína ou de uma falsificação? Os termos “APCER” e “BPCER” foram concebidos para aumentar a clareza, incluindo em seus nomes especificamente se a taxa de erro mede erros na classificação de ataques ou na classificação genuína. 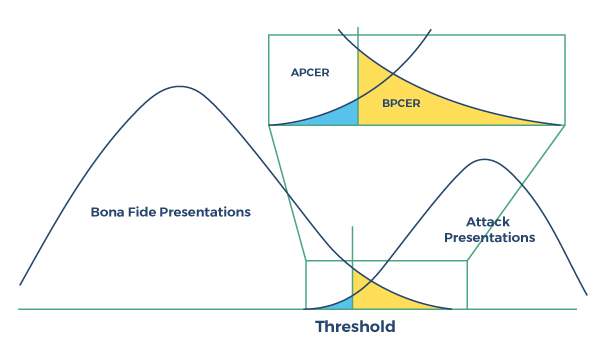 Figura: Desempenho de detecção de ataque de apresentação
Figura: Desempenho de detecção de ataque de apresentação
Assim, no caso de ataques de apresentação, graças às definições de APCER e BPCER, sabemos sempre de que tipo de taxa de erro estamos falando, com APCER representando erros de classificação de ataque e BPCER representando erros de classificação genuínos.
Visualização de desempenho: curvas DET e curvas ROC
O desempenho dos algoritmos de classificação pode ser ajustado para favorecer um resultado específico ajustando um limite, sendo o resultado uma compensação entre erros do Tipo I e do Tipo II; falsos positivos e falsos negativos. No caso de ataques de apresentação, isto significa uma compensação entre APCER e BPCER; segurança e conveniência do usuário.
As curvas DET são desenhadas para representar graficamente o desempenho de um ou mais algoritmos em uma faixa de limites e podem ser usadas para comparar rapidamente o desempenho do algoritmo. DET significa “compensação de erro de detecção” e as curvas traçam falsos positivos contra falsos negativos em seus eixos. Eles ilustram graficamente o desempenho de um classificador em termos dessa compensação; qual é o BPCER para um determinado APCER? Quanto mais próxima a linha estiver da origem, melhor será o desempenho geral.

Figura: Curva DET ilustrando o desempenho do classificador de detecção de ataque de apresentação
Os algoritmos de detecção de ataques de apresentação são análogos aos algoritmos de correspondência biométrica em muitos aspectos. Ambos são usados como classificadores e seu desempenho pode ser medido em termos de falsos positivos e falsos negativos. No caso da medição de desempenho de detecção de ataques de apresentação, as siglas APCER e BPCER preferidas pelos pesquisadores e adotadas pelo mercado são mais claras sobre o que significam. É útil lembrar que “A” significa “Ataque” e “B” significa “Bona fide”.
Termos
| Hipótese nula | No teste de hipótese estatística, o resultado observado é um resultado devido apenas ao acaso. |
| Erro tipo I
Falso positivo |
Um erro de comissão. Uma rejeição equivocada da hipótese nula; isto é, uma conclusão de que um resultado ou relacionamento se deve a mais do que apenas ao acaso, quando não o é. |
| Erro tipo II
Falso negativo |
Um erro de omissão. A falha em rejeitar a hipótese nula; isto é, uma conclusão de que um resultado ou relacionamento se deve apenas ao acaso, quando não o é. |
| APCER Taxa de erro de classificação de ataque de apresentação |
A proporção percentual na qual os exemplos de ataque de apresentação são identificados erroneamente como exemplos genuínos. Um valor mais alto indica maior vulnerabilidade de segurança. |
| BPCER Taxa de erro de classificação de apresentação genuína |
A proporção percentual na qual exemplos genuínos são identificados erroneamente como exemplos de ataque de apresentação. Um valor mais alto indica maior atrito do usuário. |
| FMR Taxa de correspondência falsa |
A proporção percentual na qual um sistema biométrico identifica incorretamente amostras biométricas de diferentes indivíduos como provenientes da mesma pessoa. |
| FNMR Taxa de falsa não correspondência |
A proporção percentual na qual um sistema biométrico identifica incorretamente amostras biométricas do mesmo indivíduo como provenientes de pessoas diferentes. |
| FAR Taxa de falsa aceitação |
Em sistemas biométricos, uma taxa de correspondência falsa em sistemas de verificação que leva em consideração a ocorrência de múltiplas tentativas e de falhas de aquisição. Um valor mais alto indica maior vulnerabilidade |
| FRR
Taxa de falsa rejeição |
Nos sistemas biométricos, uma taxa de falsa não correspondência nos sistemas de verificação que leva em consideração a ocorrência de múltiplas tentativas e de falhas de aquisição. Um valor mais alto indica maior atrito do usuário. |
| FTA Falha na aquisição |
Uma falha na coleta de uma amostra de dados, como uma imagem biométrica |
| Curva DET | Compensação de erros de detecção; um gráfico do desempenho do classificador em uma faixa de limites ilustrando taxas de falsos negativos em função das taxas de falsos positivos |